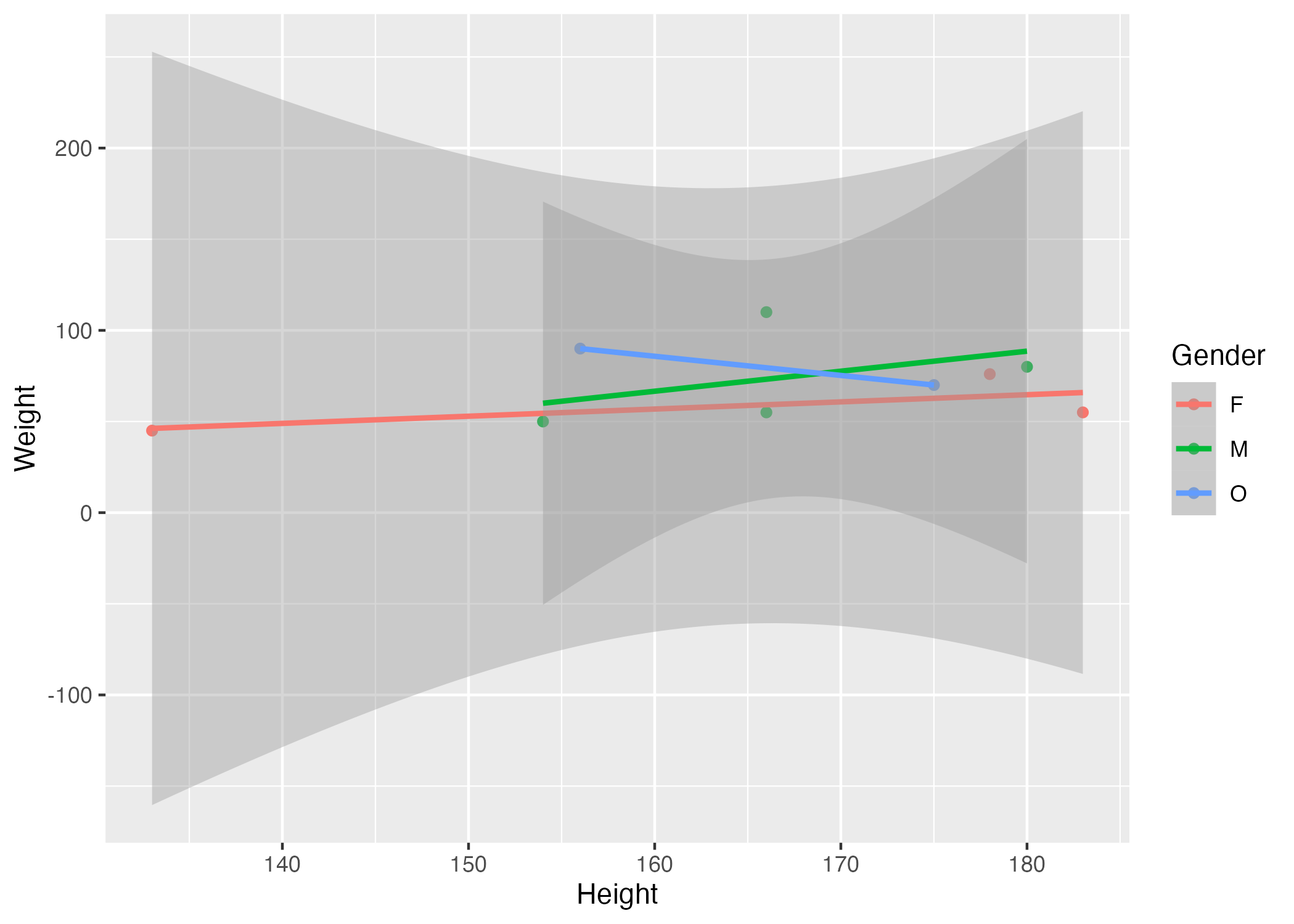
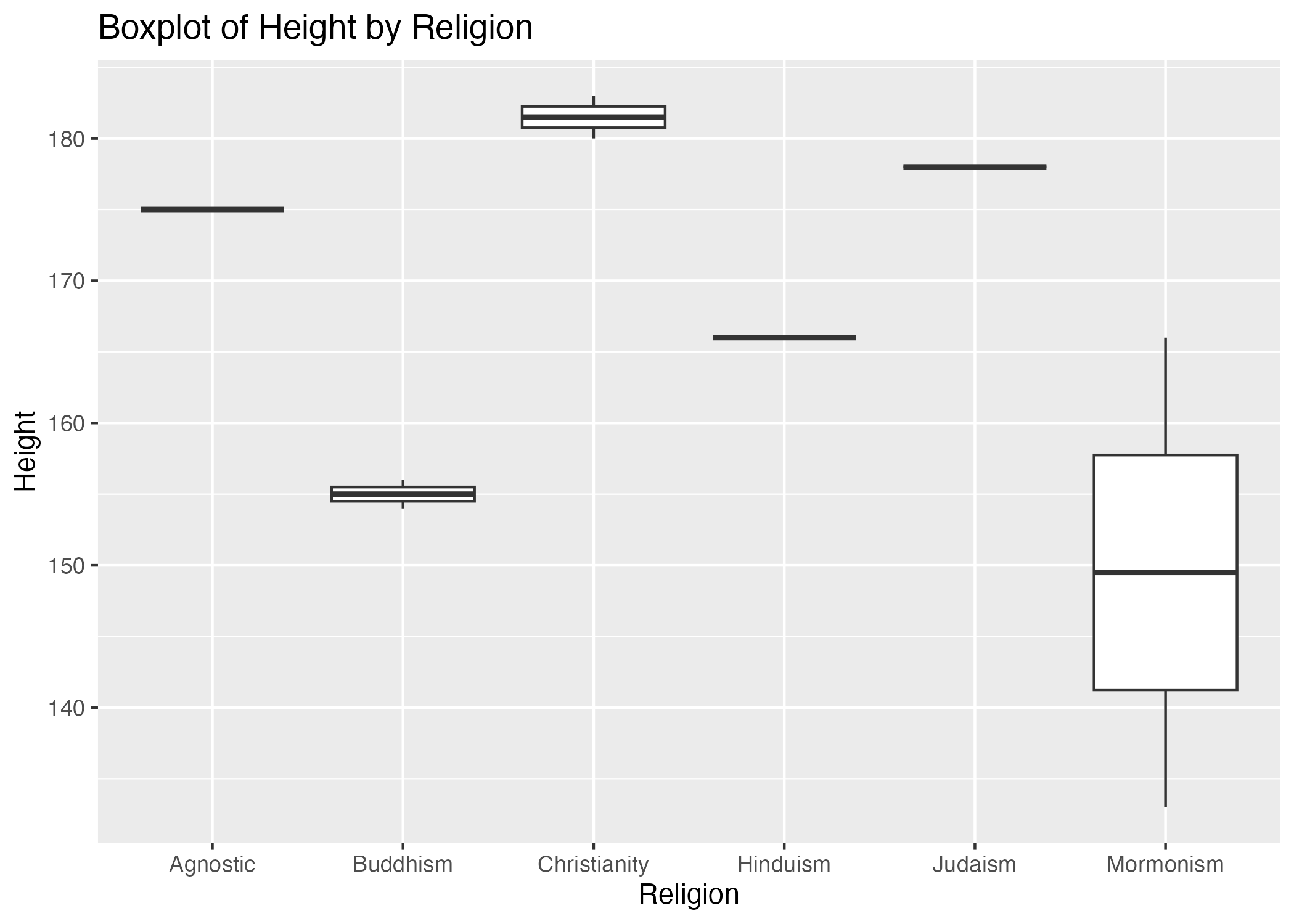
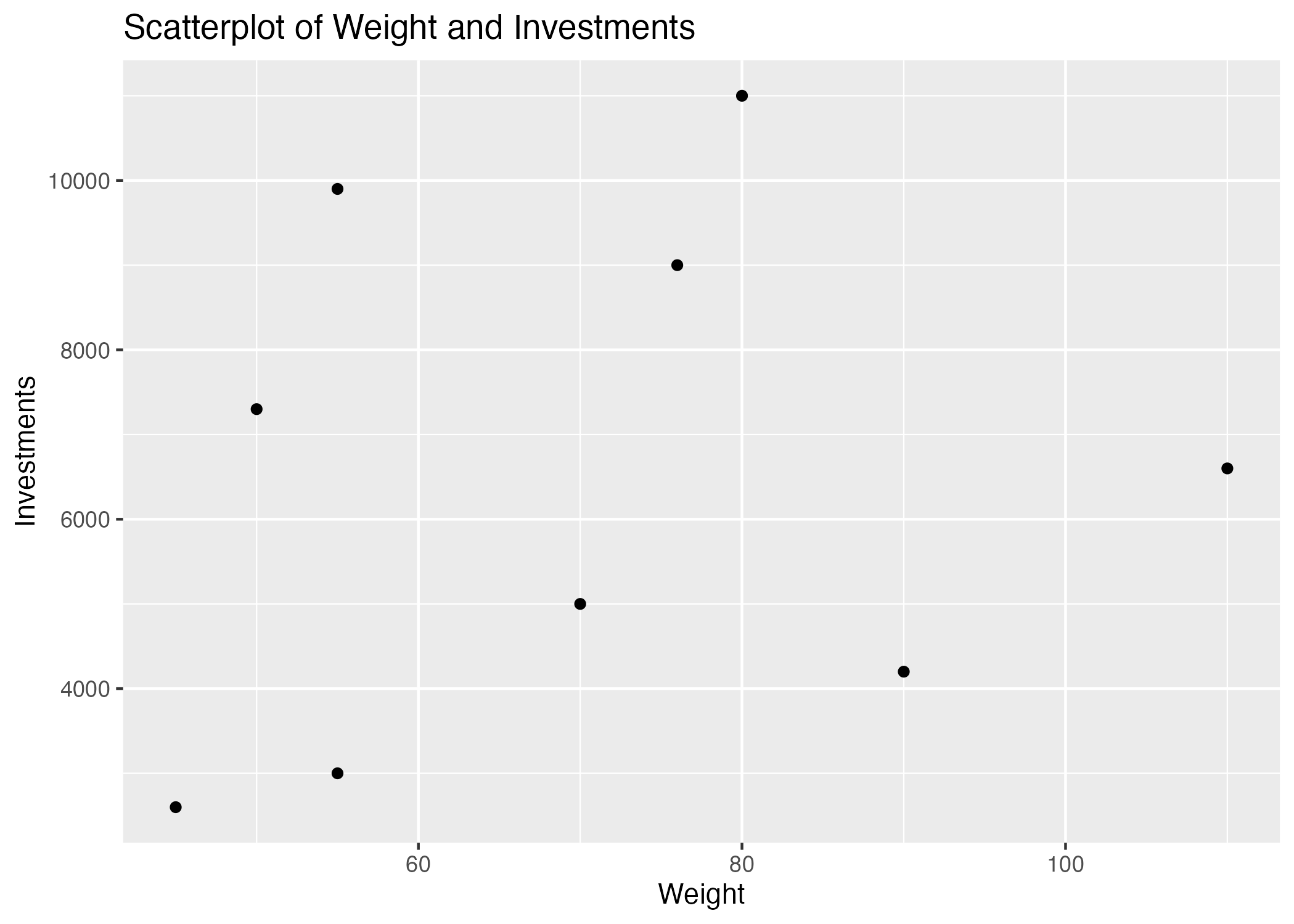
library(readxl) #for loading Excel files
library(dplyr) #for data processing/cleaning
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionlibrary(tidyr) #for data processing/cleaning
library(skimr) #for nice visualization of data
library(here) #to set paths